

There is more to Africa than the varieties of Jollof Rice delicacies or the melodious and vibeable tunes of Afrobeats.
There are African languages! With the rise of Natural Language Processing, attention has been heavily placed on western languages with several discoveries and advancements that make these languages highly resourced. However, one may ask or wonder what about African languages? What is the fate of African languages? Will they go extinct?
Good news! Our worries shall be forgotten in a short while. Help is at our doorstep beckoning us to be patient. Our dear African languages are here to stay for a long time. Borrowing Nigerian Pidgin Lingo, “e don better for us.”
Eyes are now on African languages and a lot of hands have started getting dirty trying to resuscitate our mother tongues using NLP as a strong weapon or tool for revival. Researchers have begun to spur interest in African NLP. African NLP is one to watch out for. One formidable group that is working tirelessly to expand NLP for African languages is Masakhane – a community consisting of over 1000 participants from 30 African countries with diverse educations and occupations, across the world. This group focuses on building language technologies for African languages
Recently, the group held her 3rd AfricaNLP Workshop in co-location with the prestigious ICLR 2022 Conference. The workshop was power-packed. A lot of insights were shared about African languages and how they can be developed. Let’s pretend that I am Gossip Girl for some minutes because I shall be spilling all the tea from the workshop. Grab your popcorn and a chilled bottle of coke, Ohh no! Get your pen and paper, scrap that I meant your digital devices
(we are machine learning engineers, and shouldn’t be caught doing things manually). There is a lot to be learned and a lot of work to be done to propagate our dear African languages.
The first keynote talk was given by the highly respected Uncle T, Tunde Adegbola. His focus was on Convenience, Random or Purposive Sampling: African Languages and Global NLP. He mentioned that every human language represents a cognitive window to the world, and the more languages we have access to, the more we can understand our world. He went on to say that whatever problems a language presents should be the problems that the language technologies should address.
Cristina España-Bonet talked about Low-Resource Natural Language Processing. She called African languages as languages that have low resource settings rather than low resource languages. She explored the automatic evaluation in low resource settings and the available AfricaNLP datasets. She proposed that BLEU (bilingual evaluation understudy) is a good metric to evaluate the accuracy of machine translations from one natural language.
Joyce Nakatumba-Nabende spoke about how radio and image data are used for crop disease surveillance in Uganda. She mentioned how necessary it is to build AI impact or social good that is beneficial to Uganda and Africa as a whole. She talked about Gender Bias in Luganda(which doesn’t have gendered pronouns) to English machine translation.
There were other invited talks that were discussed by Timnit Gebru; Michael Auli who talked about Zero-resource speech technology with wav2vec, and Antonios Anastasopoulos who focused on Measuring the Representativeness of NLP Datasets. There were four spotlight talks. Twenty papers were accepted and nineteen were presented at the workshop. All the papers and datasets have been linked on Lanfrica. I summarized these interesting papers in succeeding paragraphs and also attached the links to their datasets and codes. You are welcome 😊
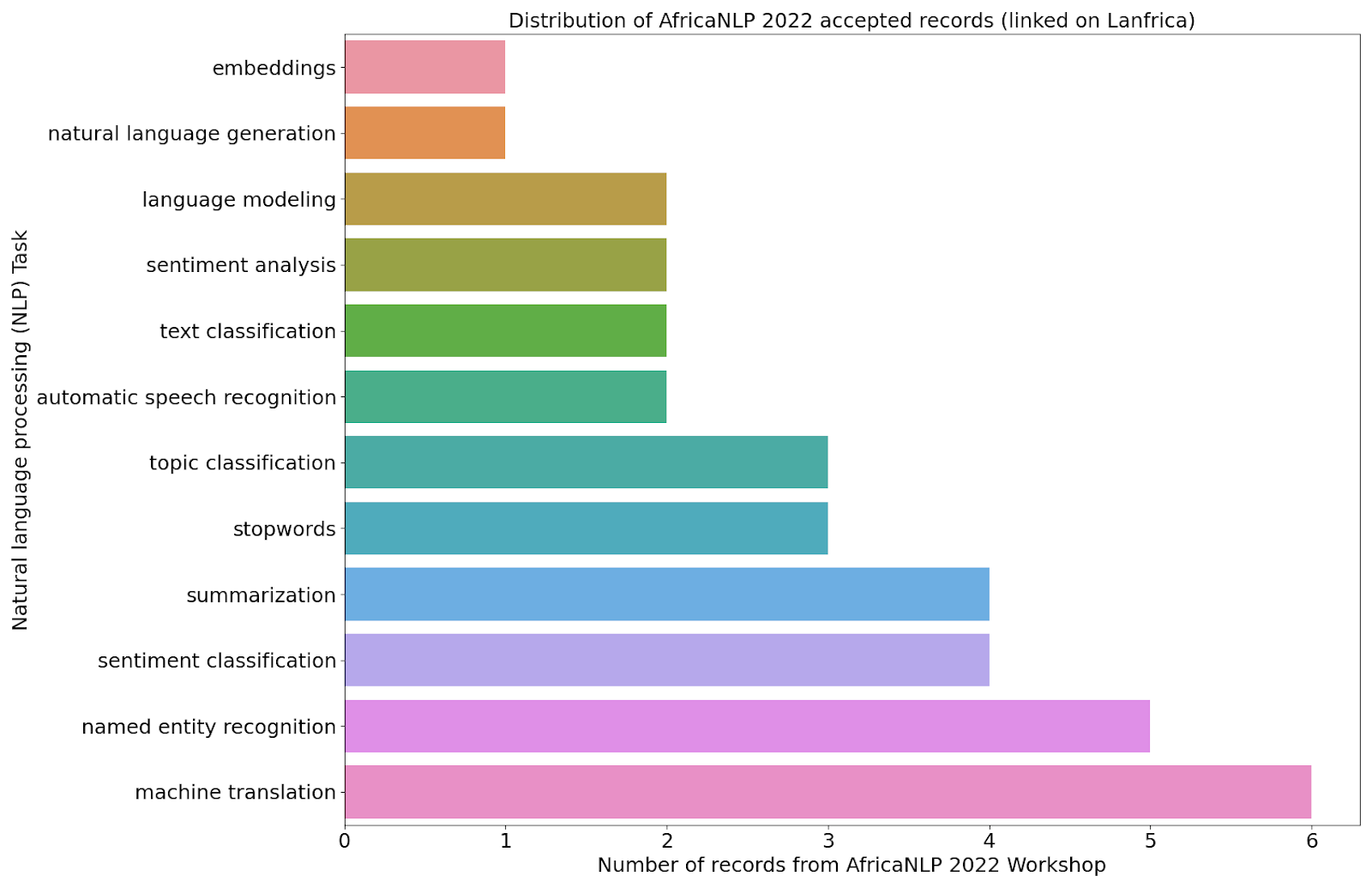
Below is the graphical representation of the various NLP tasks that researchers worked on and presented at the 2022 AfricaNLP Workshop.
Abderrahmane Issam and Khalil Mrini presented a paper on Goud.ma: a News Article Dataset for Summarization in Moroccan Darija of over 158k news articles for abstractive summarization. Goud.m was fine-tuned on the Arabic-language BERT (AraBERT), and the language models for the Moroccan (DarijaBERT), and Algerian (DziriBERT) national vernaculars for summarization.
The Igbokwenu community was not left out. Chinedu Emmanuel Mbonu and his cohorts did their magic. They created IGBOSUM – the first standard Igbo text summarization dataset.
A host of several African NLP researchers created The African Stopwords Project with the aim to curate stopwords for African languages. This ongoing project was carried out on ten African languages.
Batista and his co-authors presented a paper on a Comparison of Topic Modeling and Classification Machine Learning Algorithms on Luganda Data. Non-negative matrix factorization (NMF), classic approaches, neural networks, and some pretrained algorithms were explored to create latent topics and topic classification on Luganda data.
Claire, Andrew, and other smart people wrote a paper – Building Text and Speech Datasets for Low Resourced Languages: A Case of Languages in East Africa. This paper explored the process involved in creating, curating, and annotating language text and speech datasets for low-resourced languages in East Africa – Luganda, Runyankore-Rukiga, Acholi, Lumasaaba, and Kiswahili.
A parallel text corpus, SALT, was created for five Ugandan languages (Luganda, Runyankole, Acholi, Lugbara and Ateso) and various methods were explored to train and evaluate translation models.
Rabiu Abdullahi Ibrahim and Idris Abdulmumin described a more effective parallel data generation approach for improving low-resource neural machine translation using named entity copying and approximate translations using cross-lingual word embedding and presented NECAT-CLWE.
Akintunde and his co-authors performed An Exploration of The Vocabulary Size and Transfer Effects in Multilingual Language Models for African Languages– an empirical study that was conducted in the context of three linguistically different low-resource African languages: Amharic, Hausa, and Swahili. A
I also got the opportunity to present my paper – YOSM – the first Yoruba sentiment corpus for Nollywood movie reviews.
Dawei and his co-authors presented a paper titled “Task-Adaptive Pre-Training for Boosting Learning With Noisy Labels: A Study on Text Classification for African Languages”. They experimented with a group of standard noisy-handling methods on text classification tasks with noisy labels.
Jenalea Rajab presented the paper – Effect of Tokenisation Strategies for Low-Resourced Southern African Languages. This work made some additions to the field of neural machine translation research, for four low-resourced Southern African languages, using an optimized transformer architecture and pre-cleaned data to translate English to Northern Sotho, Setswana, Xitsonga, and isiZulu.
The religious domain was not left out. A group of 32 NLP researchers wrote a paper titled TCNSpeech – a community-curated multi-speaker sermon corpus for speech recognition tasks. It contains a total of 24 hours of English audio data recording, chunked and transcribed. The context of the dataset was domain-specific for sermons in Nigerian English accent and can be used for community data curation.
EDUSTT: In-Domain Speech Recognition for Nigerian Accented Educational Contents in English was also presented at the conference. The authors proposed an effective and reliable Automatic Speech Recognition system for education in Nigerian accent.
The authors of True Bilingual NMT proposed a true bilingual model trained on WMT14 English-French (En-Fr) dataset. For better use of parallel data, synthetic code-switched (CSW) data along with an alignment loss on the encoder to align representations across languages was generated.
The fun part about the talk was it was presented by some beautiful women of Masakhane – Wilhelmina Nekoto, Julia Kreutzer, Jenalea Rajab, Millicent Ochieng, and Jade Abbott. It was such an inspiring moment hearing women take the lead and mark the mark towards the expansion of NLP for African languages.
Dialogue Pidgin Text Adaptation via Contrastive Fine-Tuning was created to utilize the pretrained language models to address the issue of obtaining task-specific low resource language annotations for the English-derived creoles (e.g. Nigerian and Cameroonian Pidgin). It was the first parallel Pidgin-English conversation corpus in two dialogue domains.
Jesuloba Alabi and his co-authors performed Multilingual Adaptive Fine-Tuning (MAFT) on 17 most-resourced African languages and three other high-resource languages widely spoken on the continent – English, French, and Arabic to encourage cross-lingual transfer learning.
Michael Beukman presented his paper on Analysing The Effects of Transfer Learning on Low-Resourced Named Entity Recognition Performance. The study examined the properties of transfer learning between 10 low-resourced languages..
Ìtàkúròso: Exploiting Cross-Lingual Transferability for Natural Language Generation of Dialogues in Low-Resource, African Language was written by Tosin Adewumi. The study investigated the possibility of cross-lingual transfer from a state-of-the-art (SotA) deep monolingual model DialoGPT to 6 African languages – Swahili, Wolof, Hausa, Nigerian Pidgin English, Kinyarwanda and Yoruba.
“When women work together, incredible things happen.”
Wilhelmina Onyothi Nekoto (see tweet)
This for sure is a fact that I totally agree with. There was an all females MasakhaneNLP paper presentation at the Workshop Participatory Translations of Oshiwambo: Towards Sustainable Culture Preservation with Language Technology by Wilhelmina Nekoto, Julia Kreutzer, Jenalea Rajab, Millicent Ochieng, and Jade Abbott. The created data of this work spanned from diverse topics of cultural importance and comprised over 5,000 sentences written in the Oshindonga dialect and translated to English, the largest parallel corpus for Oshiwambo to date. These women are working towards building one million indigenous datasets. Love to see it! So inspiring!
As one that had the privilege to write a paper and present it at the workshop, I must say writing a paper is definitely not an easy walk in the park.The hard work of all the organizers of the workshop and paper authors needs to be applauded. They did a good job!
Three Gbosas for the organizers of the Workshop!!!
Three hearty cheers for the authors of the papers!!!
Long Live African NLP!!!