
The last few months have been full of activity at Lanfrica, and we are happy to announce that Lanfrica is officially launched.
Why Lanfrica?
Lanfrica aims to mitigate the difficulty encountered in the discovery of African language resources by creating a centralized, language-first catalog.

For instance, if you’re looking for resources (linguistic datasets or research papers) in a particular African language, Lanfrica will point you to the different sources on the web that have such datasets in the desired language. In the deficient case, we adopt a participatory approach by allowing you to contribute (with papers, datasets). Read more about the motivation and scope of Lanfrica in our About section.
At Lanfrica, we employ a language-focused approach. With 2199 African languages accounted for, our language section boasts of ALL the African languages (yes all of them …including the extinct ones). At Lanfrica, we have created algorithms that can tell, with much effectiveness, the African language(s) involved in a resource, enabling us to even curate works that do not explicitly specify the African languages they worked on (which are very many).
Lanfrica offers huge potential for better discoverability and representation of African languages on the web. Lanfrica is able to give useful statistics on the progress of African languages. As a simple illustration, from the language filter section, you get an immediate overview of the number of existing natural language processing (NLP) resources for each African language. Based on this, one can easily see that for South African languages, Afrikaans has 28 NLP resources, Swati has just 8 ….or that the Gbe cluster languages of Benin have far less NLP resources than some of the South-African languages. Such insight can lead to better allocation of funds, efforts, etc towards bringing the more under-researched languages forward in NLP – thereby fostering the equal progress of African languages.
This launch is just the beginning (v1). We have major updates coming up in the future:
- One of such updates is to enable our users to sign up and add/edit the resources on Lanfrica.
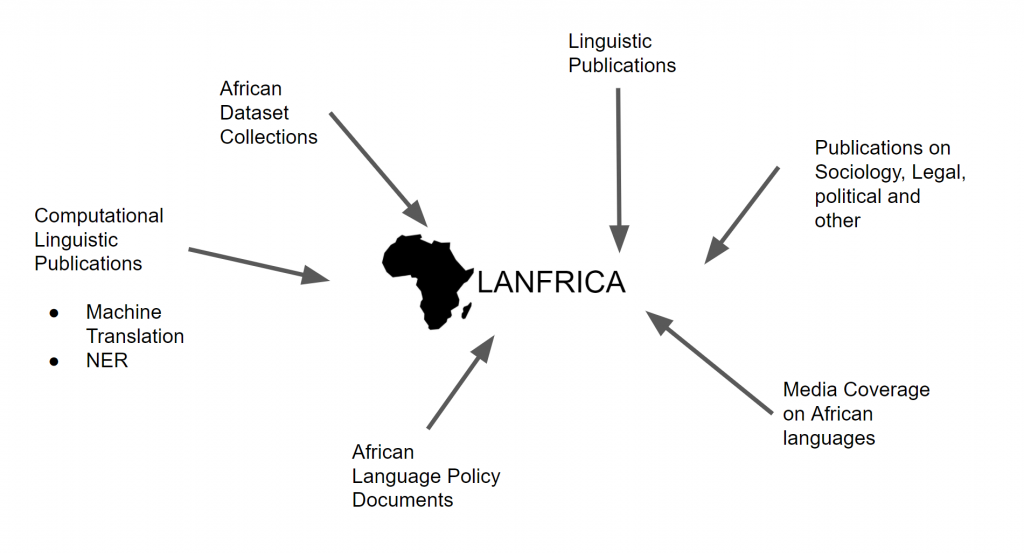
- Our current resources currently consist of NLP datasets. Next we plan to work on publications in Computational Linguistics > Linguistic Publications, etc. See the
“Vision”section of our About section for the full picture. - We are exploring a variety of techniques to greatly simplify the process through which relevant resources are identified and connected to Lanfrica.
For more updates as we move forward,
- Be part of the Lanfrica community by joining our Slack.
- Follow us on Twitter.